Endpoint Configuration
Webhook triggers can be configured for an integration in one of two ways, depending on your needs:
- Instance and Flow Specific: Each flow on each instance gets its own unique endpoint. This is the default configuration.
- Instance Specific: Each instance gets a unique endpoint, and the integration determines which flow to run based on header or payload data.
When deciding on a webhook endpoint configuration, ask yourself two questions:
- Do my webhook endpoints need to be the same for each of my instances, or can instances be configured to use different webhook endpoints?
- If my instances can have unique webhook endpoints, can webhooks be configured to send data to unique endpoints depending on what activity they're responding to? For example, if a third-party app invokes an integration when it has an inventory update or when a new order is created, can those two activities be configured to invoke distinct webhook endpoints?
Once you have answers to those questions, you can choose the appropriate webhook endpoint configuration.
Selecting endpoint configuration
To configure your integration's endpoint settings, click the Endpoint Configuration button on the right-hand side of Builder. From the Endpoint Type input, select one of the three endpoint types listed above.
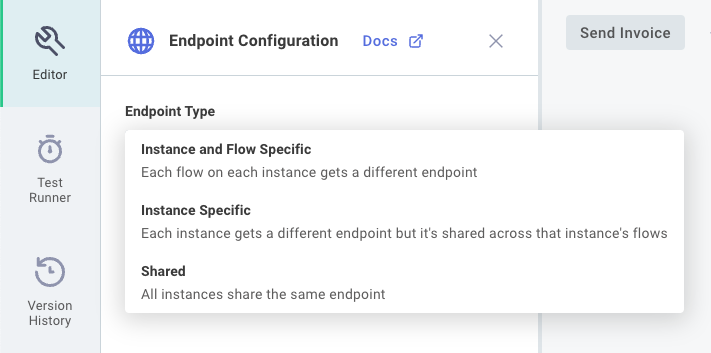
Depending on what endpoint type you choose, you will be presented with different configuration options (described next).
Instance and flow-specific endpoint configuration
This is the default configuration. When an instance is deployed, each flow within the instance is assigned its own webhook endpoint.
Instance A's "Update Inventory" flow has a unique endpoint that is different than Instance A's "Process Order" flow endpoint, and different than Instance B's "Update Inventory" flow endpoint.
Integrations that use this endpoint configuration often set up webhooks with a deploy trigger, and remove them with an instance remove trigger.
Instance-specific endpoint configuration
When an instance is deployed, that instance is assigned a single webhook endpoint. The flows that comprise the instance all share that endpoint. Each instance has a unique endpoint, so Instance A of the "Acme ERP" integration will have one endpoint, and Instance B of the same integration will have a different endpoint.
If flows share an endpoint, which flow is executed? Since several flows share an endpoint URL, you need a way to determine which flow should run when data is sent to your endpoint. You can determine which flow to run in two ways:
- Without a preprocess flow. You can send the name of the flow that should run as an HTTP header or as a value in the HTTP payload.
- With a preprocess flow. You can designate one flow of your integration to be a preprocess flow - that flow will determine which sibling flow should run.
Instance-specific endpoint without a preprocess flow
If you do not use a preprocess flow, you can send the name of the flow to run as an HTTP header or as a value in the HTTP payload.
Flow name from HTTP payload
For example, you could send the name of the flow you'd like to execute as part of your payload like this:
curl https://us-east-2.elasticpathintegrations.com/trigger/EXAMPLE== \
--location \
--header "Content-Type: application/json" \
--data '{"myFlowName":"Update Inventory","item":"widgets","quantity":5,"state":"removed"}'
Within the Endpoint Configuration drawer, you could choose to reference results.body.data.myFlowName to determine which flow to run:
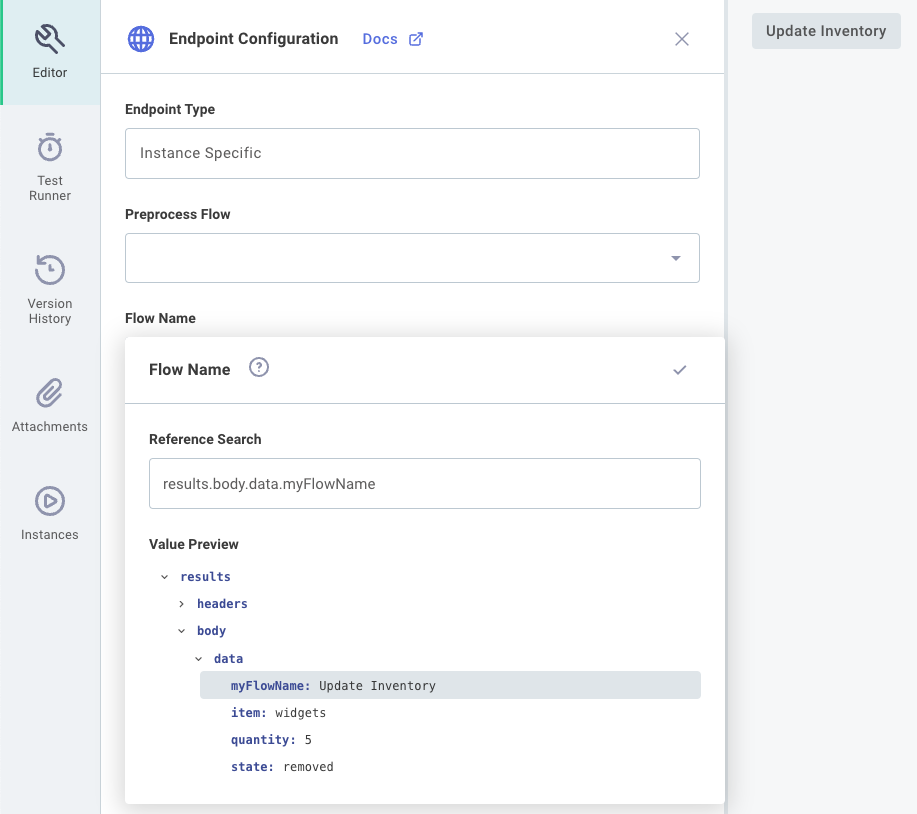
Given the curl invocation above, the Update Inventory flow would be run with the rest of the payload that was provided.
Run a test of endpoint configuration In order to populate the result picker in the screenshot above, click TEST RUNNER and then open the Endpoint -> Payload tab. Enter a sample payload and click Save & Test Endpoint. Your test data will be available in the result picker menu in the Endpoint Configuration drawer.
Flow name from HTTP header
If you'd like to pass flow name as an HTTP header instead, a curl invocation could look like this:
curl https://us-east-2.elasticpathintegrations.com/trigger/EXAMPLE== \
--location \
--header "Content-Type: application/json" \
--header "myflowname: Update Inventory" \
--data '{"item":"widgets","quantity":5,"state":"removed"}'
In that case, you would reference results.headers.myflowname to determine which flow to run:
Per HTTP RFC 2616, HTTP headers should be case-insensitive. We've found HTTP clients to be inconsistent about their behavior and implementations, though. Postman, for example, will send camel-cased headers, while others will always lower-case header keys.
We recommend that you use lower-case HTTP header keys to avoid compatibility issues.
Instance-specific endpoint with a preprocess flow
If you need additional logic to determine which flow to run (for example, if you need to inspect an XML payload's shape to determine what kind of data was received), you can leverage a preprocess flow. This flow executes when data is sent to the instance's endpoint. It can be comprised of any number of steps, and the last step's results determine which sibling flow to execute.
To configure a preprocess flow, first build a flow that can inspect an incoming payload, and verify that the last step returns the name of the flow that you'd like to run next. Then, open the Endpoint Configuration drawer, select your preprocess flow from the Preprocess Flow dropdown menu, and under Flow Name select the key representing the name of the flow that should run:
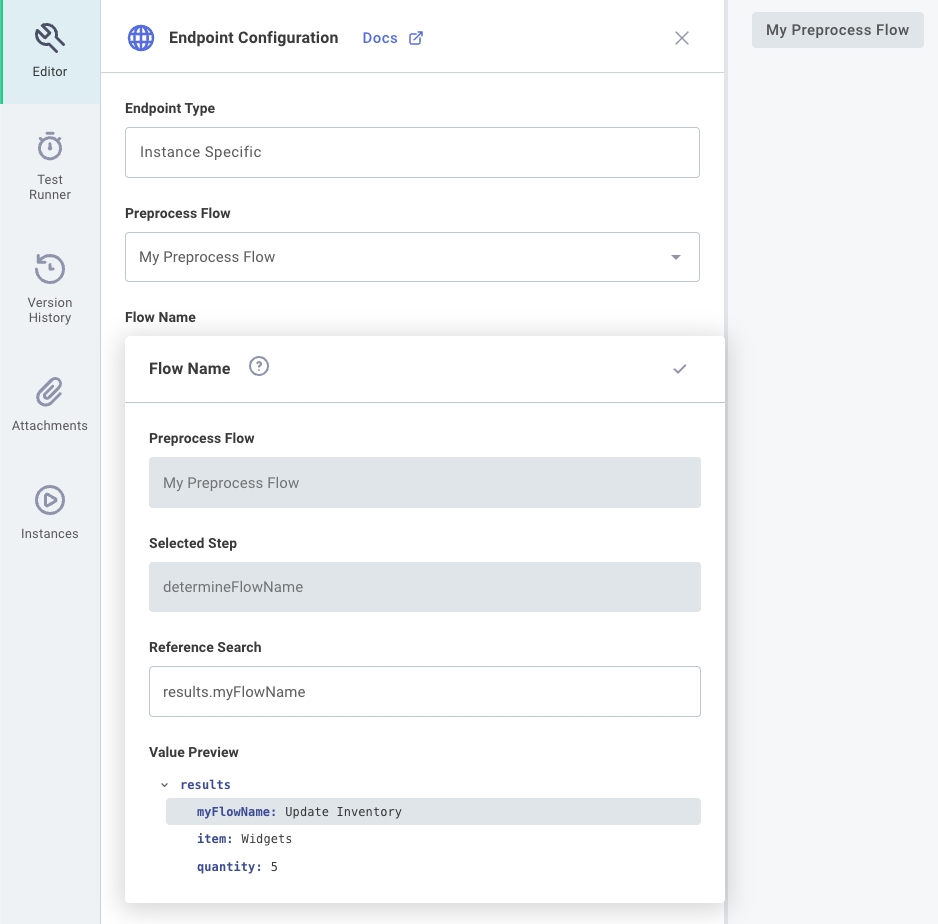
You may need to run a test of your preprocess flow in order to populate the result picker in the Endpoint Configuration drawer.
Testing endpoint configuration
You can test each of your flows individually (including a preprocess flow, if applicable) by clicking the SAVE & TEST FLOW button on the top right of Builder. If you would like to test your endpoint configuration, click the arrow icon to the right of SAVE & TEST FLOW, and toggle the dropdown to Test Endpoint Configuration. Then, you can click SAVE & TEST ENDPOINT to test your endpoint configuration.
To configure a test payload, open the TEST RUNNER drawer, select the Endpoint tab, and then select the Payload tab. You can enter the payload and any headers that you would like to send to the shared endpoint.
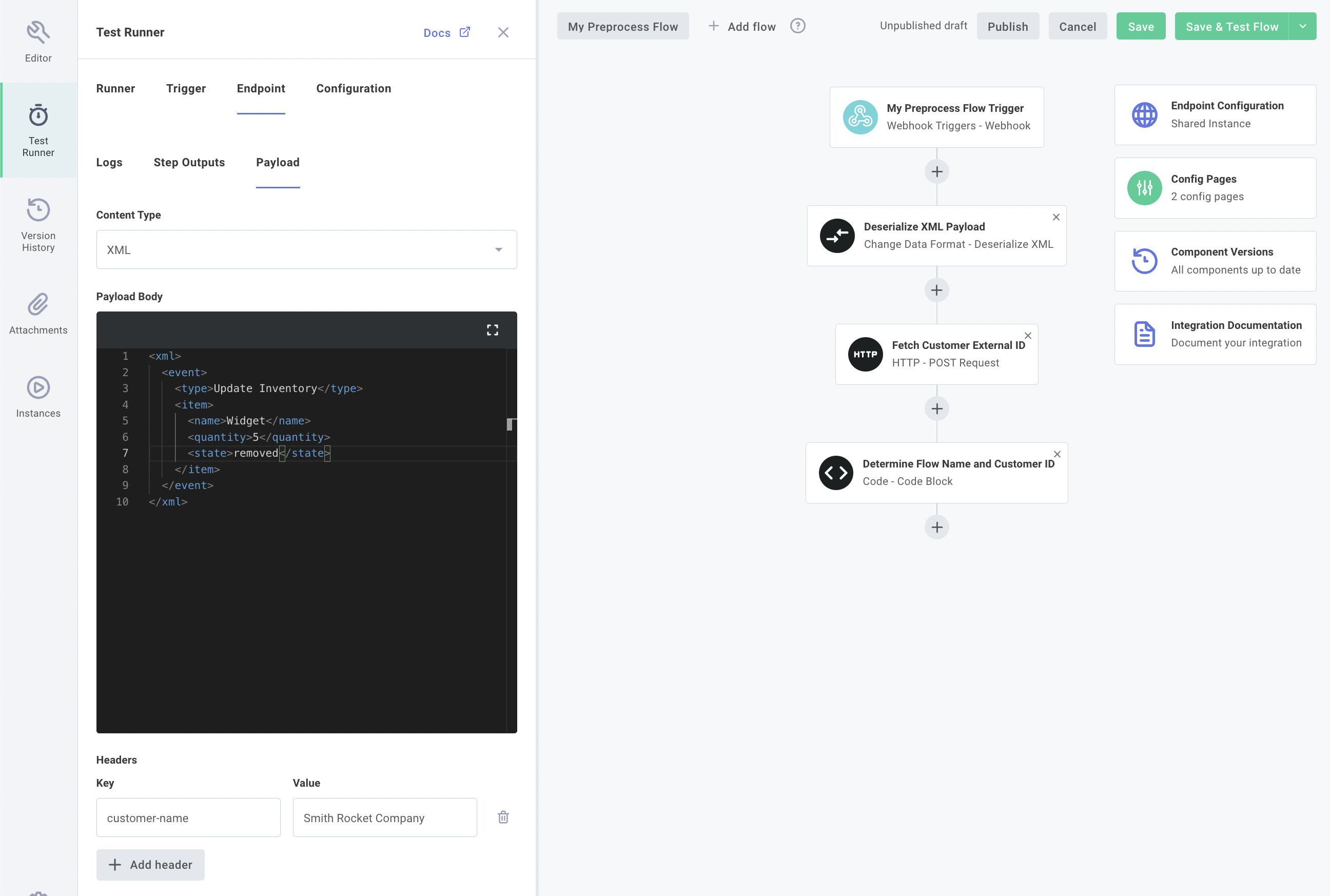
Within the Logs and Step Outputs tabs you will see logs and step results for both the preprocess flow (if you have one), and the flow that the request was routed to.
If an error is thrown (for example, the flow name that the preprocess flow generated was not found), that error will appear in the Logs tab.
Builder is a sandbox. No test invocations will go to your existing instances.
Troubleshooting shared endpoints in production
If you have an integration with Instance-Specific Endpoint Configuration, then all logs and execution records will appear in the instance's execution results page. Executions that that run through a preprocess flow that then trigger a sibling flow are packaged together as one execution in the executions page. If your instance's preprocess flow throws an error or yields the name of a flow that doesn't exist, you can see those errors and step results from that page.