Looping Over Files in GCS Bucket
In this tutorial we will build an integration that downloads and processes files stored in Google Cloud Storage.
For this integration, assume that some third-party service writes a file to a Google Cloud Platform (GCP) storage bucket whenever an order is processed.
We'll configure our integration to run every five minutes, and our integration will do the following:
- Look for files in the
unprocessed/directory of our GCP Storage bucket - Loop over each file that we found:
- Download the file
- Deserialize the JSON contained in the file
- Do some data mapping
- Post the transformed data to an HTTP endpoint
- Move the file from the
unprocessed/directory to aprocessed/directory
Our integration will take advantage of the loop component to process files one by one.
If you do not have a Google Cloud Platform (GCP) account, you can use Dropbox, Box, Amazon S3, Azure Blob Storage, etc., instead. They all have similar list files, download file and move file actions.
List files
We'll start by adding a Google Cloud Storage List Files action to our integration. This will automatically create a Google Cloud Storage to our config wizard. Under the Bucket Name input, we'll click Config Variable tab and create a new config variable to represent bucket name:
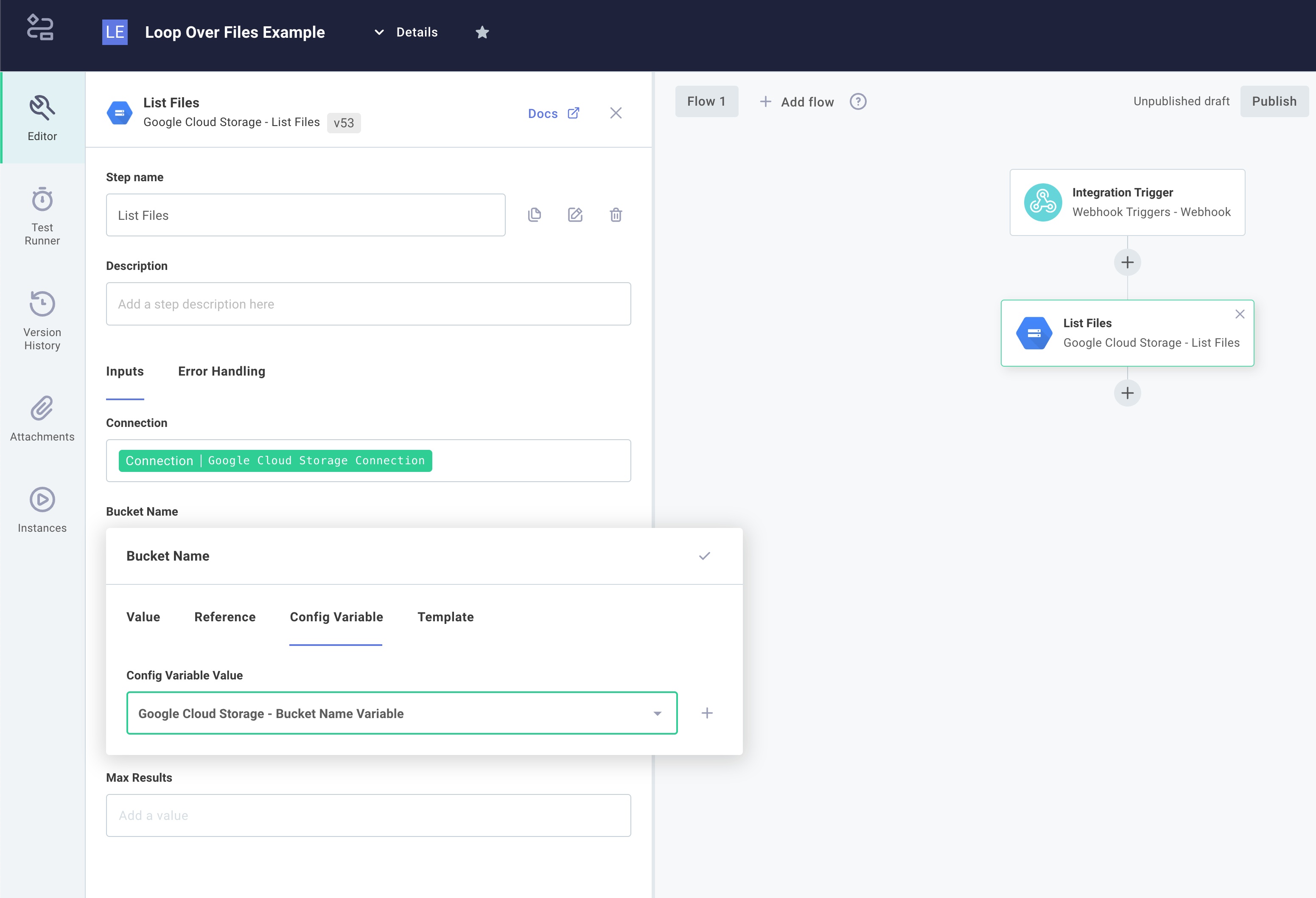
Under Prefix, enter unprocessed/, so it only displays files in the unprocessed/ directory of the bucket.
Next, we'll open the Test Runner drawer and select Save & Reconfigure Test Instance to set some test credentials.
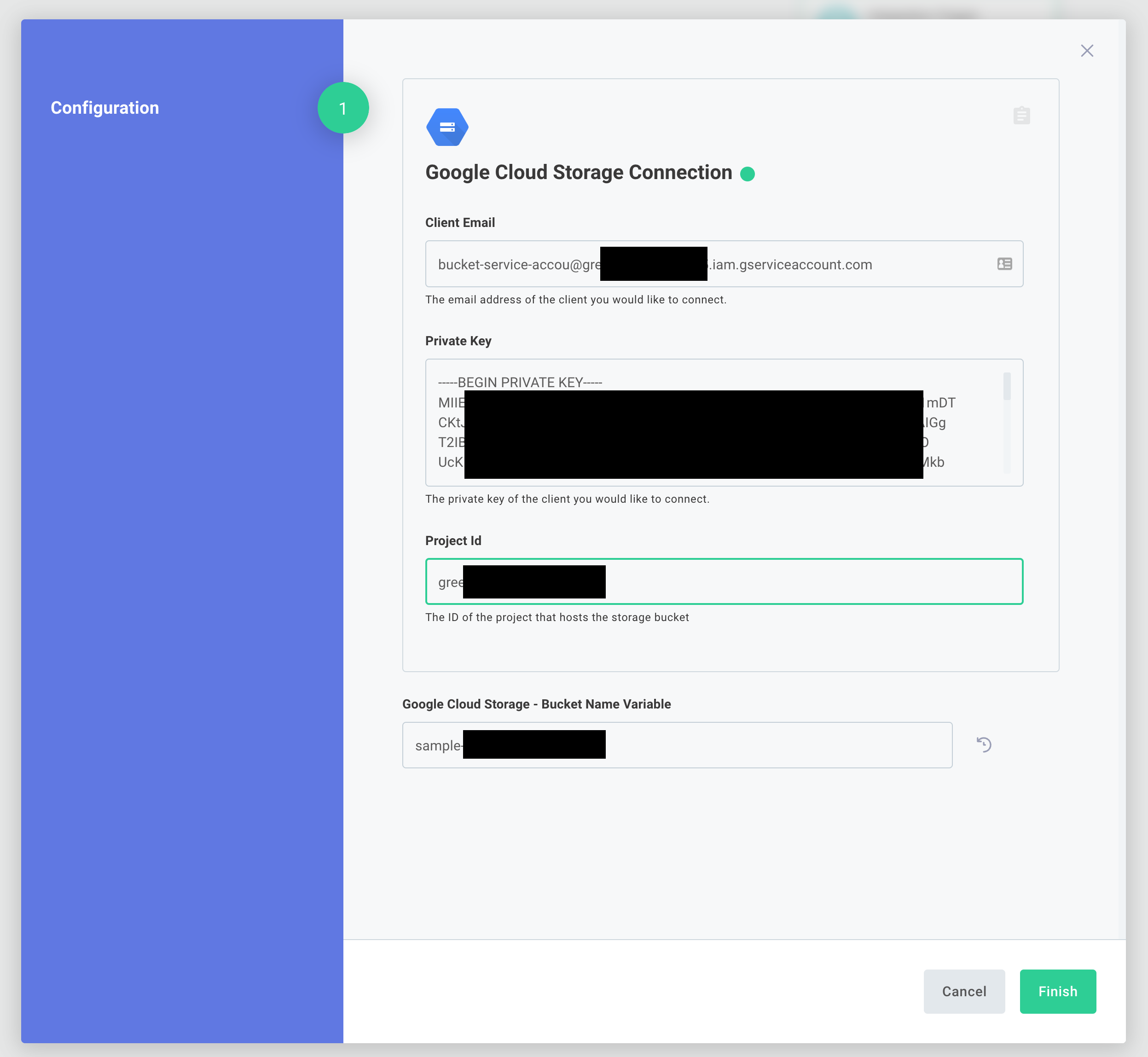
Finally, we'll click Save & Run Test.
If you see any errors about permissions, ensure that the Google IAM account you created as the proper permissions to the bucket you created.
You should see the files in your unprocessed/ directory:
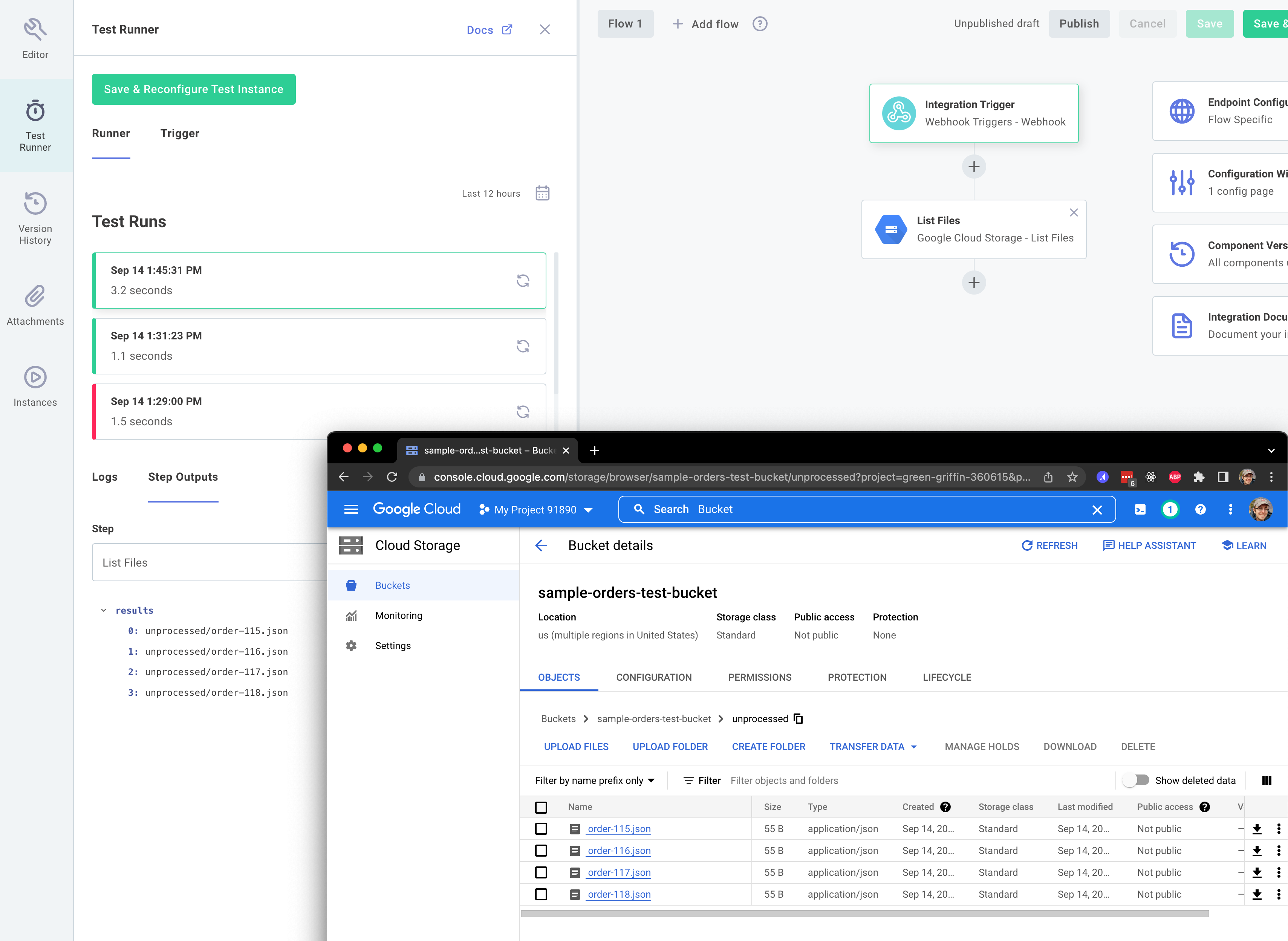
Create our loop
Next, we'll loop over the files that our List Files step found. We'll add a Loop Over Items step.
Under the Items input we will reference the list of files our previous step returned:
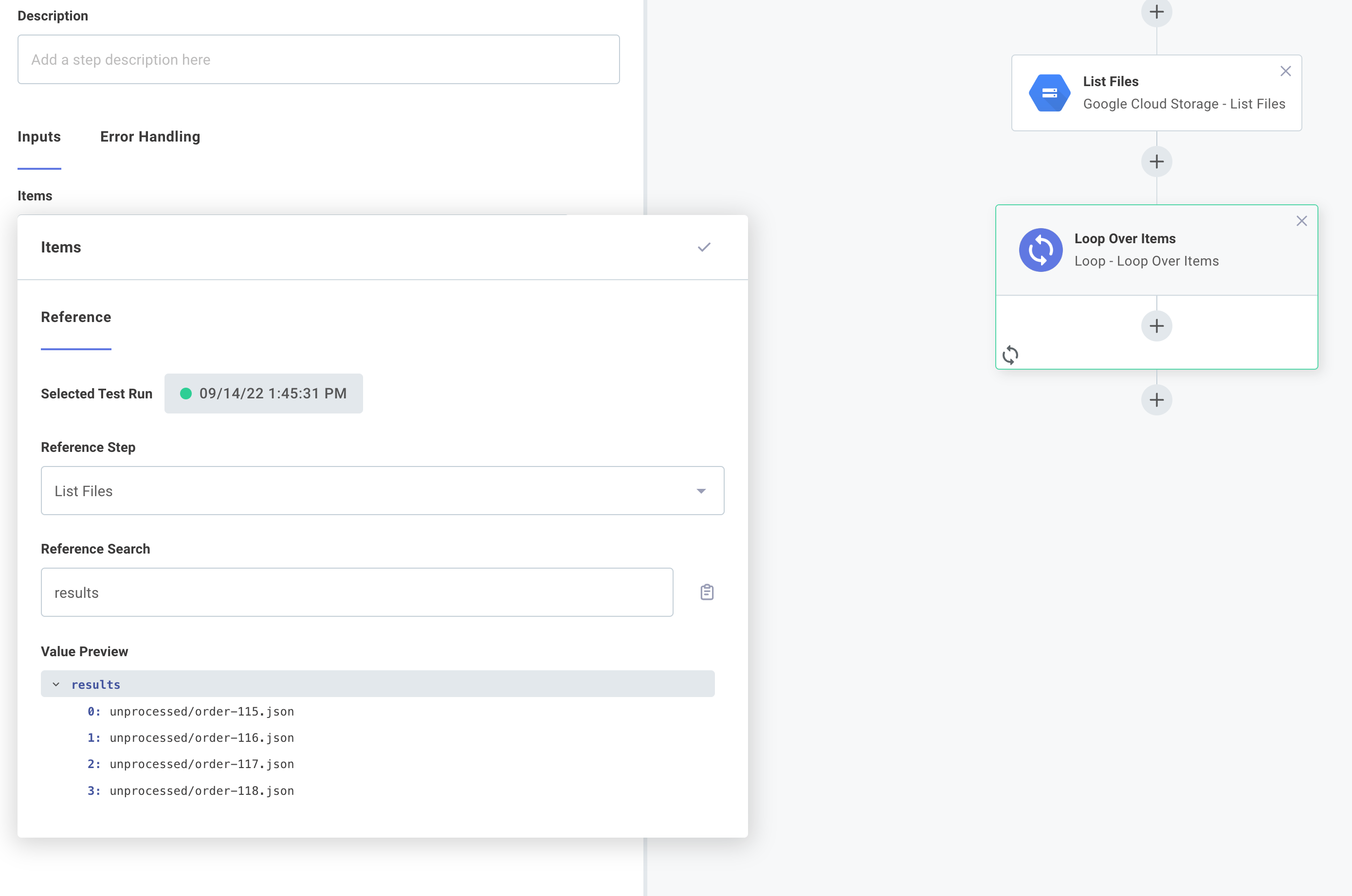
Add tasks to the loop
Our loop is now configured to run once for each file that was found in the unprocessed/ directory in our GCP bucket.
Our loop will contain a few steps to process and send the data to an external system:
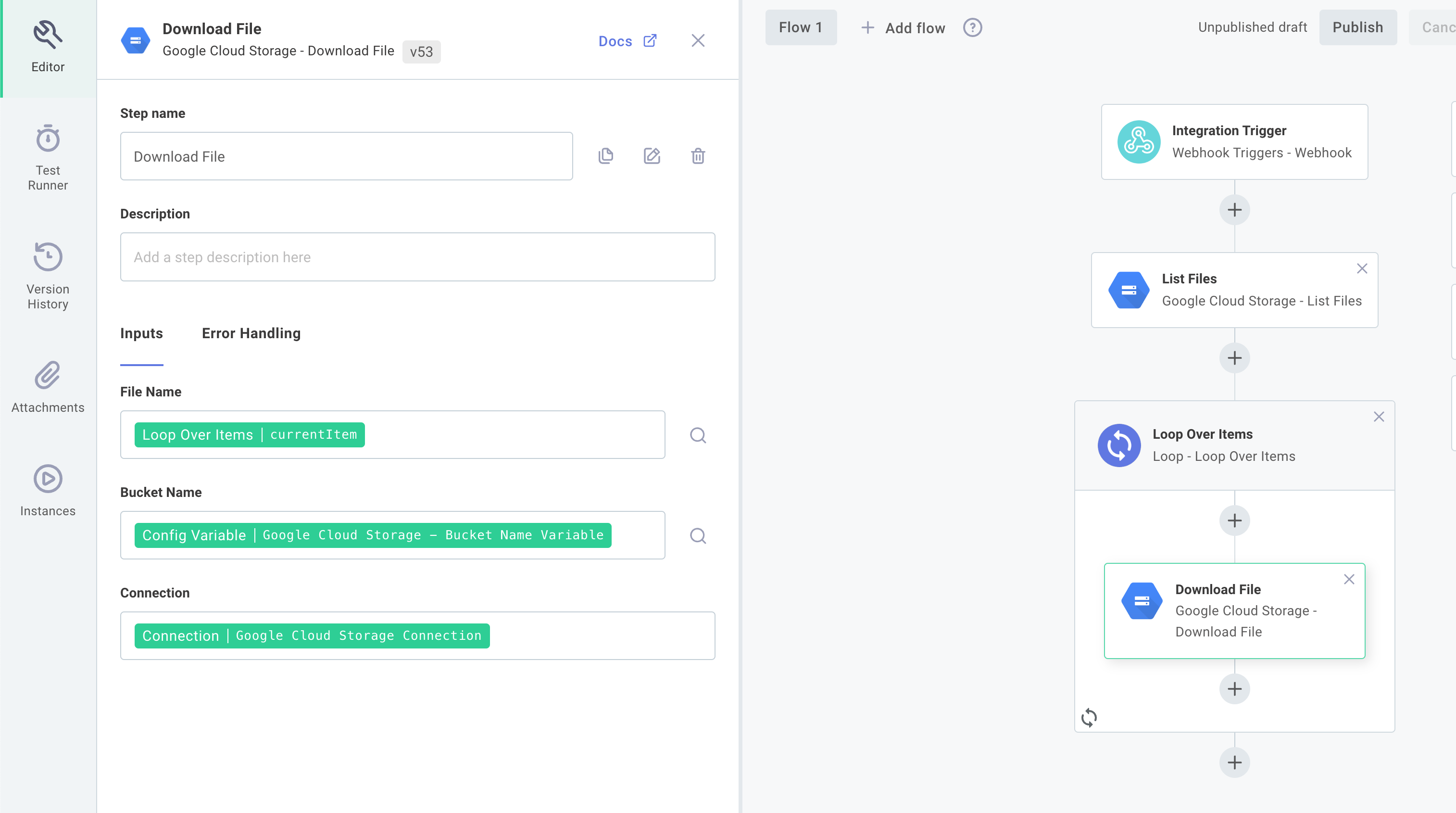
Download the file we're currently looping over
First, we'll download the file we're currently looping over.
The item that we're currently processing from our is accessible using the currentItem key of the loop.
We'll add a Download File action from the GCP component.
- For File Name we'll reference the loop's
currentItem. - For Bucket Name we'll reference the bucket name config variable we created.
- Our Connection is already set up for us.
For example, if there's a file named
unprocessed/20210322_163522.jsonin our bucket,loopOverEachFile.currentItemwould be equal to"unprocessed/20210322_163522.json":
Because we're downloading a JSON file, the JSON is automatically parsed for us. If we'd downloaded an XML file, CSV, file, etc, we could have leveraged a Change Data Format step to deserialize the file.

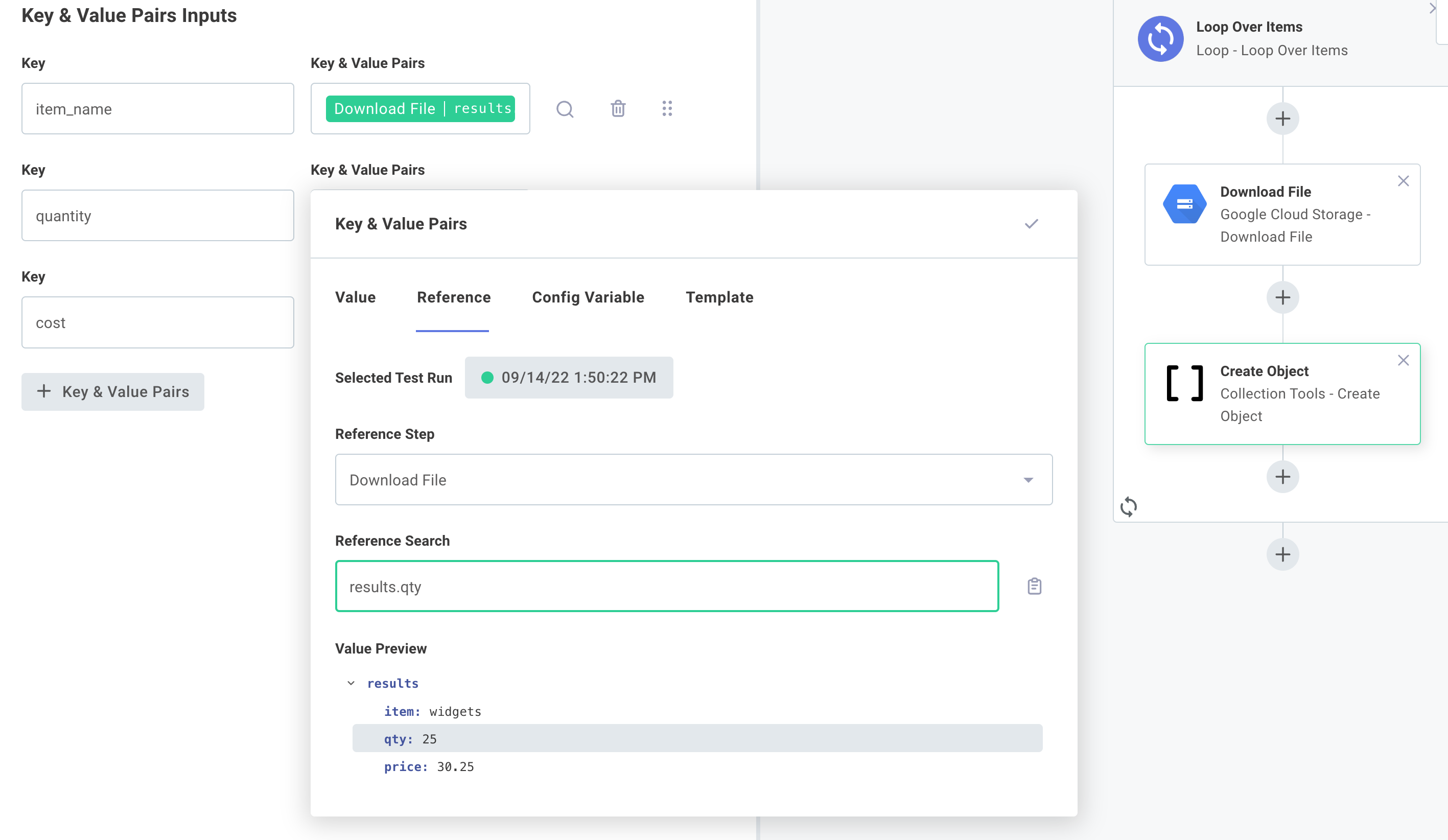
Map the data
Next, suppose the API we're sending the data to expects a different format ("quantity" instead of "qty", etc). We can use the Collection Tools Create Object action to create a new object for us, referencing the results of the Download File step:
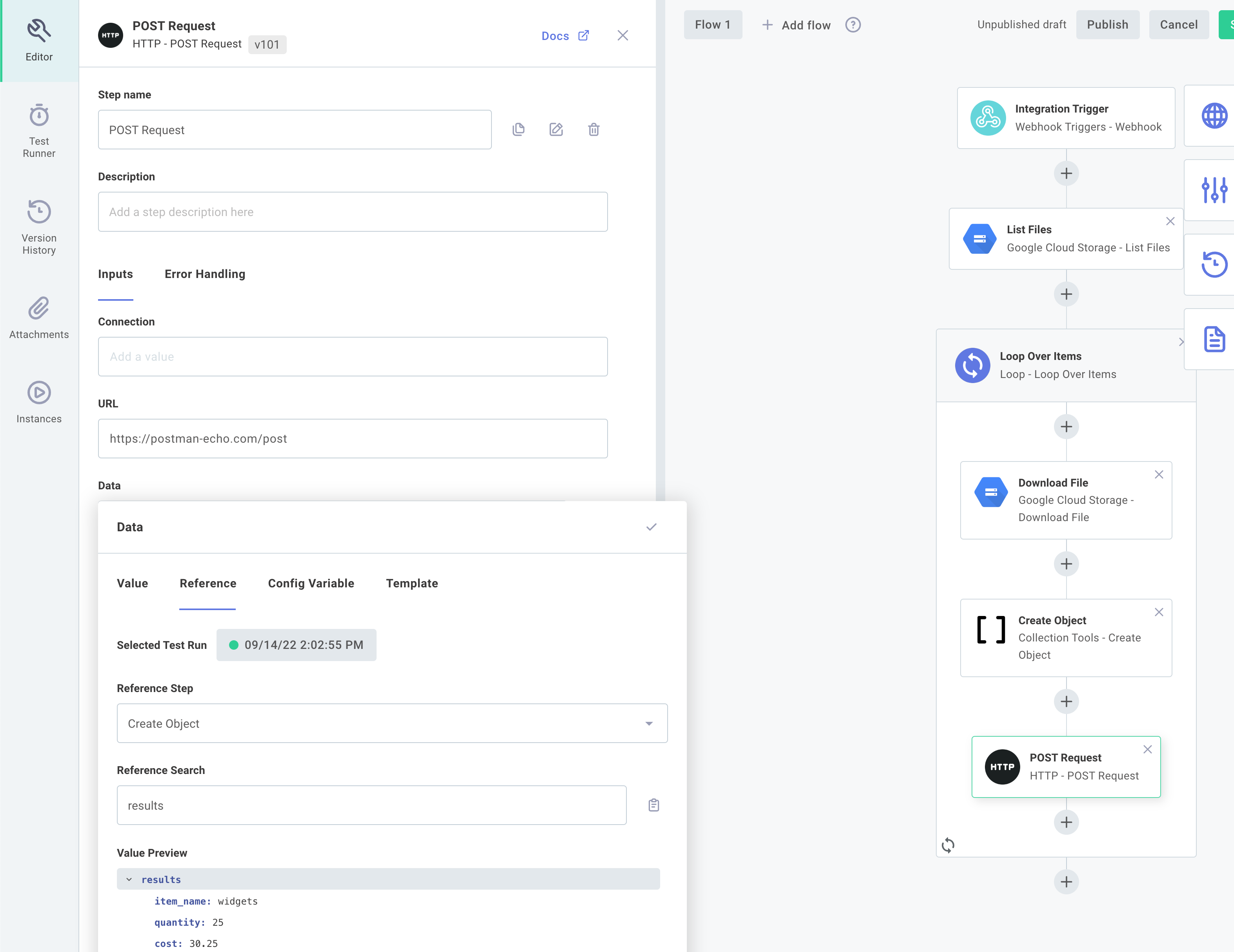
Send the data
Next, we'll use the HTTP component's POST Request action to send the data we generated. As a placeholder for an external API, we'll post the data to Postman's endpoint. For our Data input, we'll reference the Create Object's results:
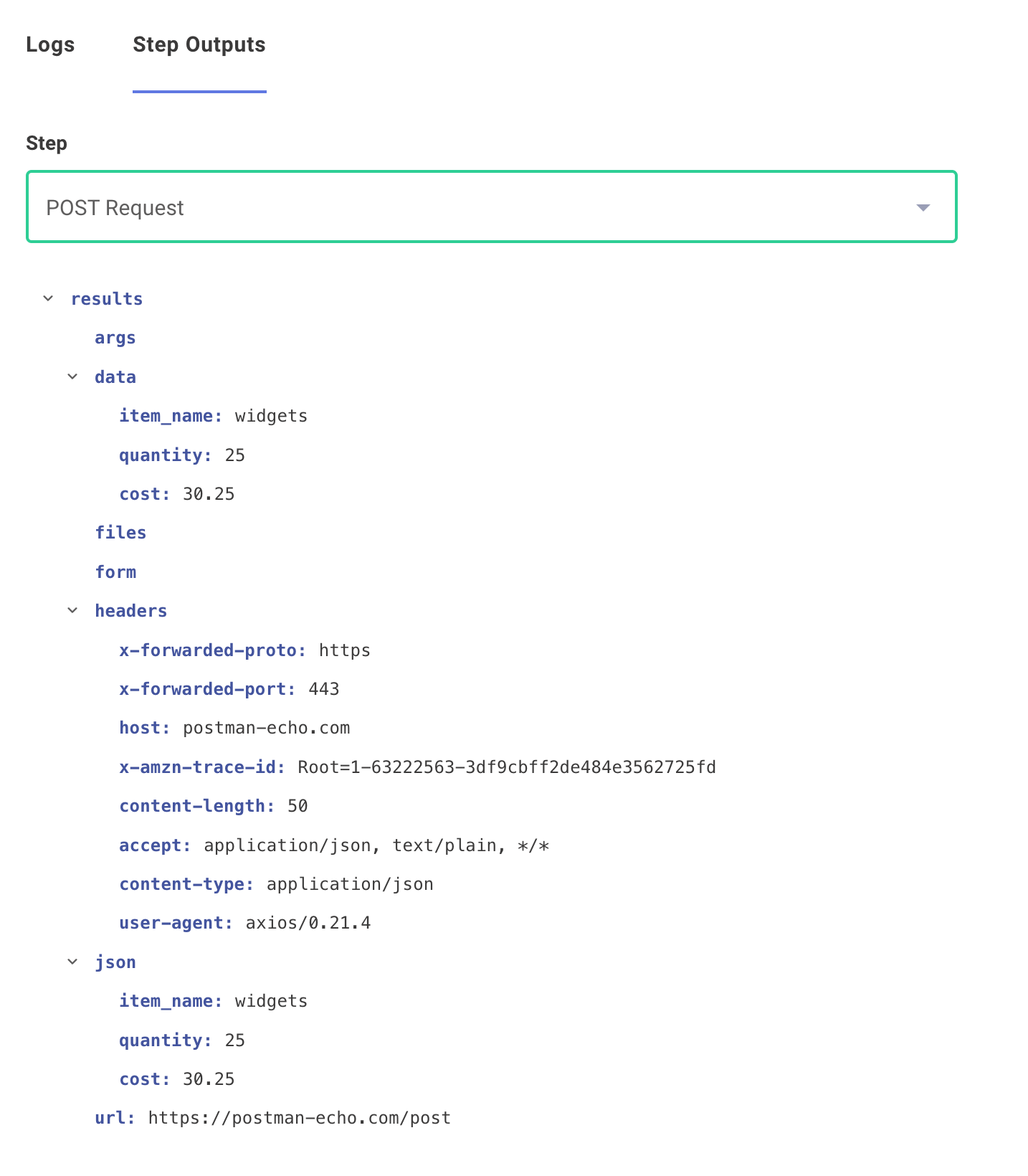
If we run Save & Run Test again, we can see the results of the POSTed data:
Move the file to a processed directory
Finally, we'll move the file that we downloaded out of the way by moving the file from unprocessed/ to processed/.
First, we need to replace the word unprocessed with processed.
We'll use the Text Manipulation component's Find & Replace action for that, once again referencing the loop's currentItem:
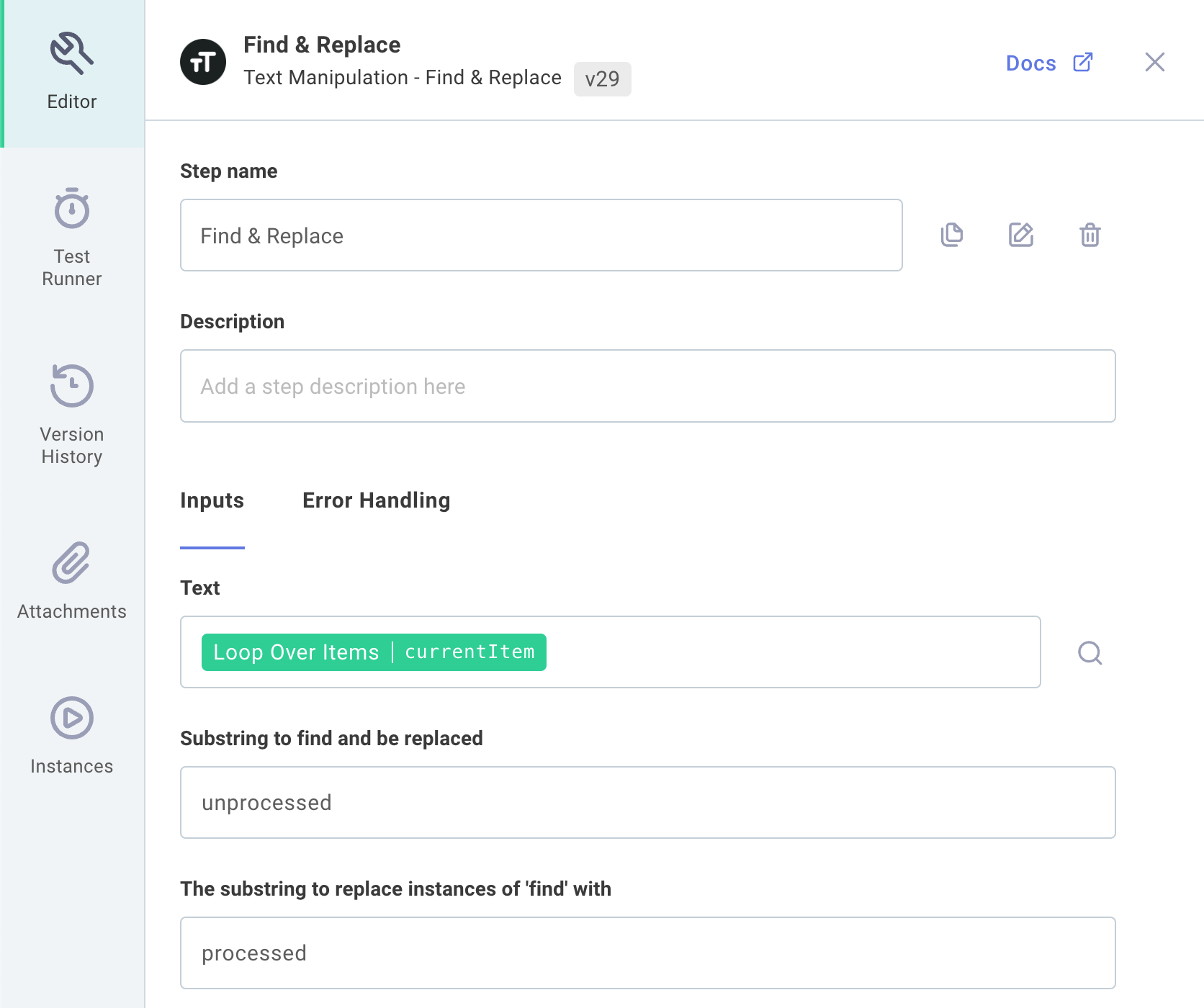
We'll add a Google Cloud Storage Move File action to move our folder from one folder to another:
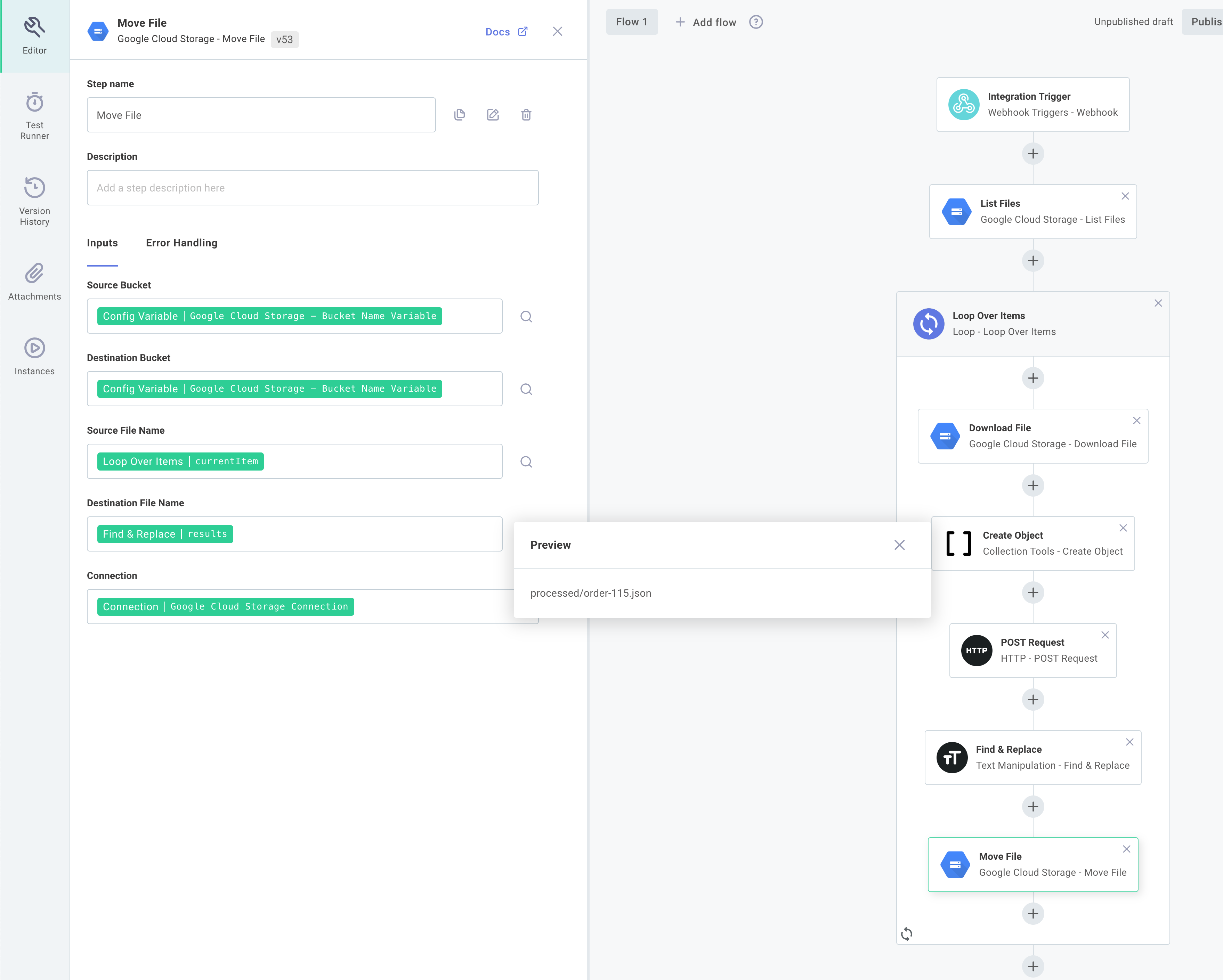
Conclusion
That's it! At this point we have an integration that loops over files in a directory, processes them, and sends the data to an HTTP endpoint. This integration can be published, and an integration can be configured and deployed.